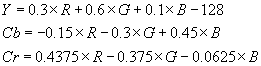
The JPEG standard defines four variations for compression of images. These are known as follows
Sequential DCT based mode: This is the JPEG baseline format. The bulk of this report discusses this style
Sequential lossless mode: This format is defined for applications in which it would be desirable to have no image detail lost in the compression process. This is not widely used as the compression statistics for this method is modest compared to the other styles.
Progressive DCT based mode: This format is very similar to the Baseline mode, however instead of processing information in one scan of the image, this mode processes in a serious of scans, each one better defining the image from the last scan that was processed.
Hierarchical mode: This format allows a number of different resolution images to be held within one file. This means that only one image file needs to be made for a number of resolutions it could be viewed at. Again it uses more than one scan to define the image, the decoder simply uses scans in order until it has reached the resolution it requires.
JPEG Baseline is the defacto standard that is used, and is the version for which this project is based. The reasons for this are that is the simplest algorithm as well as being the most widely supported because the JPEG standard specifies that all JPEG decoders MUST support the baseline version, even if it uses some of the other features within the JPEG standard.
A number of concepts need to be developed before JPEG encoding can be discussed in depth.
The JPEG standard is applicable to both grey scale and colour images. This is done by breaking a picture down in to a number of components. When each component is put together, the end image can be viewed. For example a back and white image would have only one component which would depict the grey scale of the image, whereas a colour image generally has three components (one for each primary colour, red green and blue or equivalent).
Each component is made up of x columns and y rows of samples. These samples are simply the actual "pixel" data of the image. In JPEG Baseline the number of samples is the same as the resolution of the image. A single pass through a component and its samples is known as a scan. In JPEG Baseline this does not mean a great deal as only one scan of the image is used.
In JPEG encoding the data is broken into a number of blocks called Minimum Coded Units (MCU’s). These MCU’s are simply made by taking a number of 8x8 pixel sections of the source image. MCU’s are used to break down the image into workable blocks of data as well as to allow manipulation of local image correlation at a given part of the image by the encoding algorithm.
When processing each MCU, the algorithm always moves through the component from the left to right, then top to bottom order.
There are two methods of processing MCU’s and components. The first method is whereby each MCU contains data from a single component only, and hence is comprised of only one unit of data. The second method is where the data from each component is interleaved within a single MCU. This means that each MCU contains all the data for a particular physical section of an image, rather than a number of MCUs containing each component of that section. This project uses the latter option
Further to this, there are horizontal and vertical sampling factors. These sampling factors dictate how many 8x8 pixel sections are to be placed within an MCU when the component data is interleaved. For this project, the simplest option was taken which is a horizontal and vertical sampling factor of 1.
A number of inherent properties of images and the human visual system can be manipulated to allow for greater compression through the JPEG algorithm.
One of these is the tendency for the human eye to notice variations of brightness intensity much more than variations of colour in an image. The JPEG algorithm can take advantage of this by applying different rules for brightness and colour variations.
Another property is that real world images generally do not have sharp boundaries for brightness intensity changes and colour changes. This means that spatial frequencies detected within an image are generally low order, ie gradual change rather than quick changes over a localised area of an image.
The JPEG algorithm generally does not use the RGB (Red, Green, and Blue) colour format. Instead it uses a derivative of this called YCbCr (Luminance and Chrominance).
The YCbCr colour format is ideal for JPEG compression as it enables brightness and colour information from an image to be separated. This is desirable as, described previously, the human eye tends to notice brightness variation more then colour variation. By separating these two properties we can apply different tolerances and compression ratios to each so as to get optimal compression at the best image quality possible.
The RGB colour scheme is simply a method of storing the Red, Green and Blue colour components of a pixel. It uses a byte of data per colour component for full colour (or 24 bit) values. In other words, each colour component has a range of 0 to 65535 for the value of the colour being described. Note that this is not the same as 16 bit colour which allows only a subset of the 24 bit colour field.
Taking the RGB values and inputting them into a set of equations as follows derives the YCbCr colour format coefficients,
where R, G, B and Y are unsigned 8 bit numbers
and Cb and Cr are signed 8 bit numbers
This gives 8 bit values for the Brightness and the two Chrominance coefficients. This now gives more meaningful variables for the JPEG algorithm to work with.
JPEG Algorithm Technical Details
The JPEG Baseline algorithm can be broken broadly down into three sections as follows
Discrete Cosine Transform (DCT)
Quantisation
Entropy Coding
A discussion of each follows
The Discrete Cosine Transform is used in JPEG encoding to produce uncorrelated coefficients, allowing effective compression as each coefficient can be treated independently without risk of affecting compression efficiency.
An additional feature of the DCT is that it allows the ability of quantising the DCT coefficients using visually weighted quantisation values to increase compression efficiency. This process is discussed later in the report.
A number of ways exist to compute the DCT, each with various speed optimisations. For the purposes of this project, the simplest but slowest method was used to ensure the most reliable results.
The human visual system is very dependent on spatial frequencies within an image. The DCT allows us to approximately break down an image into a set of waveforms, each with a particular spatial frequency. In doing this we can discard information that is not perceptible to the human visual system and keep the information that it is important to it.
The DCT uses an 8x8 two-dimensional array of samples (ie an 8x8 pixel section of the original image) as input to the algorithm. Each sample is an 8 bit number representing the specific component currently being processed. Output from the DCT is an 8x8 set of spatial frequencies representing the input section of the image. Each number output from the DCT is a 12 bit number.
The DCT itself is a relatively complex mathematical equation as follows
![]()
where
![]() for z = 0
or
for z = 0
or
![]() for z >
0
for z >
0
![]() - 2-D sample
value
- 2-D sample
value
![]() - 2-D DCT
coefficient
- 2-D DCT
coefficient
The DCT output matrix represents magnitudes of spatial frequencies of increasing order. The lowest order is the (0,0) position (top left) and increases in each direction. The (0,0)-position value or lowest order is the average value of the input matrix. It is also known as the DC coefficient. All the other values are known as AC coefficients.
For example if a 8x8 matrix to be input into the DCT algorithm was filled with the value 5, then the output matrix would have a 5 value in the DC coefficient, and zero in all the other 63 AC coefficients. This is due to the average of the input matrix being 5, as well as there being no spatial frequency change throughout the input. Ie the input matrix was monotonous.
One of the advantages of using a DCT process as JPEG does is that real world images often have very gradual changes in brightness and colour. This leads, generally, to very low (often zero) values in the high frequency coefficients of the DCT output. This is manipulated in the Quantisation section of the JPEG Baseline algorithm.
As mentioned before there are algorithms known as "Fast DCTs". These algorithms can speed up the process quite considerably. For example a DCT calculated on a 8x8 array of samples using the equation shown above will use 1024 multiplications and 896 additions to process the DCT. Using one of the fast DCT that has been developed by Feig requires only 54 multiplications, 464 additions and 6 arithmetic shifts to produce a similar result. This project does not make use of these methods, as it is not one of the goals to produce a ‘fast’ JPEG encoder.
For decompression, the decoder uses an inverse of this equation as follows
![]()
where
![]() for z = 0
or
for z = 0
or
![]() for z >
0
for z >
0
![]() - 2-D sample
value
- 2-D sample
value
![]() - 2-D DCT
coefficient
- 2-D DCT
coefficient
The second step of the JPEG algorithm is the quantisation process. To quantise the output of the DCT we divide this matrix by an integer matrix of the same dimensions.
The act of quantising the output of the DCT is what introduces the "lossy" aspect of the JPEG algorithm. It also enables one of the main compression features that JPEG is able to perform.
As mentioned previously, images tend have low spatial frequency changes in a localised area. Combined with the tendency for humans to not notice high spatial frequency changes, this allows a large amount of the high order spatial frequency coefficients to be discarded. This is implemented by choosing the quantisation factors appropriately for the coefficient to be quantised.
For example, the DC coefficient data is important to retain, so a small quantisation factor is chosen for it. Typically this is around 10 to 16. Conversely the highest order AC coefficient (7,7) is not important to retain so a large quantisation factor is chosen. Typically this number can range between 80 to 140. The other AC values are generally graded between the two extremes.
Obviously the higher the quantisation factor, the closer to zero the coefficient is going to become. This property is taken advantage of in the Huffman Entropy encoding. Note that the values are always rounded to integers, so the information that is lost is in the rounding of coefficients after being quantised. This also explains why large quantisation factors are more likely to discard information.
The ability to have different quantisation factors depending on the component being processed is also specified in the JPEG standard. As was mentioned previously brightness and colour separation in the YCbCr colour scheme is beneficial for JPEG as the two quantities have different perceptions in the human eye. It follows that it would be beneficial to have different quantisation factors for the brightness and the chrominance values as we can discard more chrominance and not readily notice the difference. Hence two different quantisation factor tables are generally defined for colour images, one for the Y (or brightness) component, and one for the Cb and Cr components (or chrominance). Of course if the image were a grey scale image with only one component, then only one quantisation factor table would be required. The JPEG standard allows at most four quantisation factor tables to be defined in an image.
It is common to see a normal 8x8 pixel section of an image represented by two or three numbers in the DC and low frequency AC coefficients and the rest of the quantised coefficients being zero. Obviously this is a very compressible format (a large number of repeated predictable constants).
To set up the quantised data for the Entropy encoding procedure, the current matrix format is not particularly useful. Since the quantised coefficients have a greater chance of being zero as the order of the spatial frequency values increases it would be beneficial to arrange the coefficients in this order. Ie to somehow arrange the coefficients so that the data was in a one dimensional array sorted from the DC value to the highest order spatial frequency (7,7). This is done by zig-zag ordering. The following diagram illustrates the sorting algorithm.
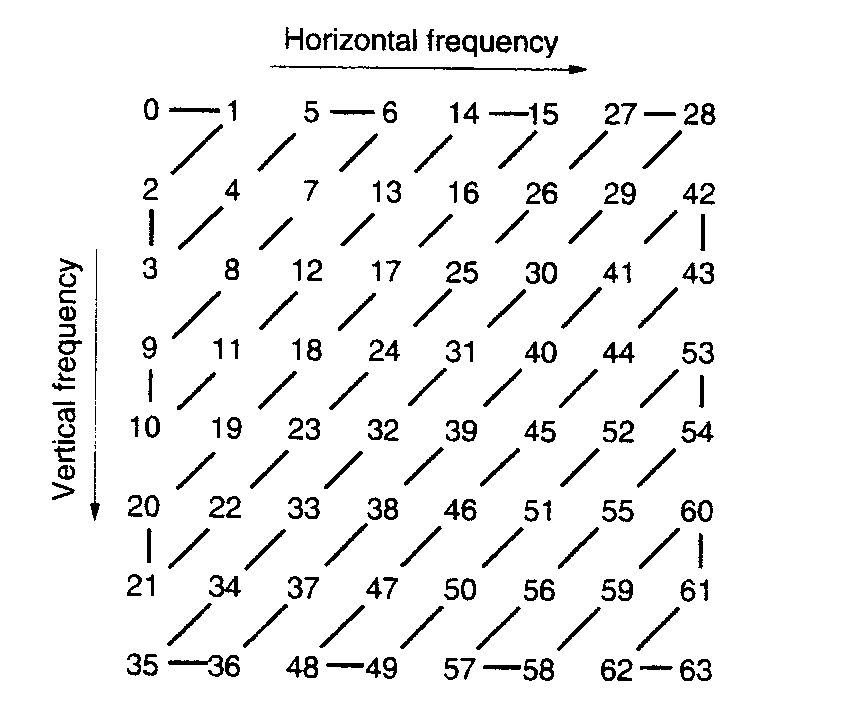
Zig Zag Sorting Order for the DCT [1]
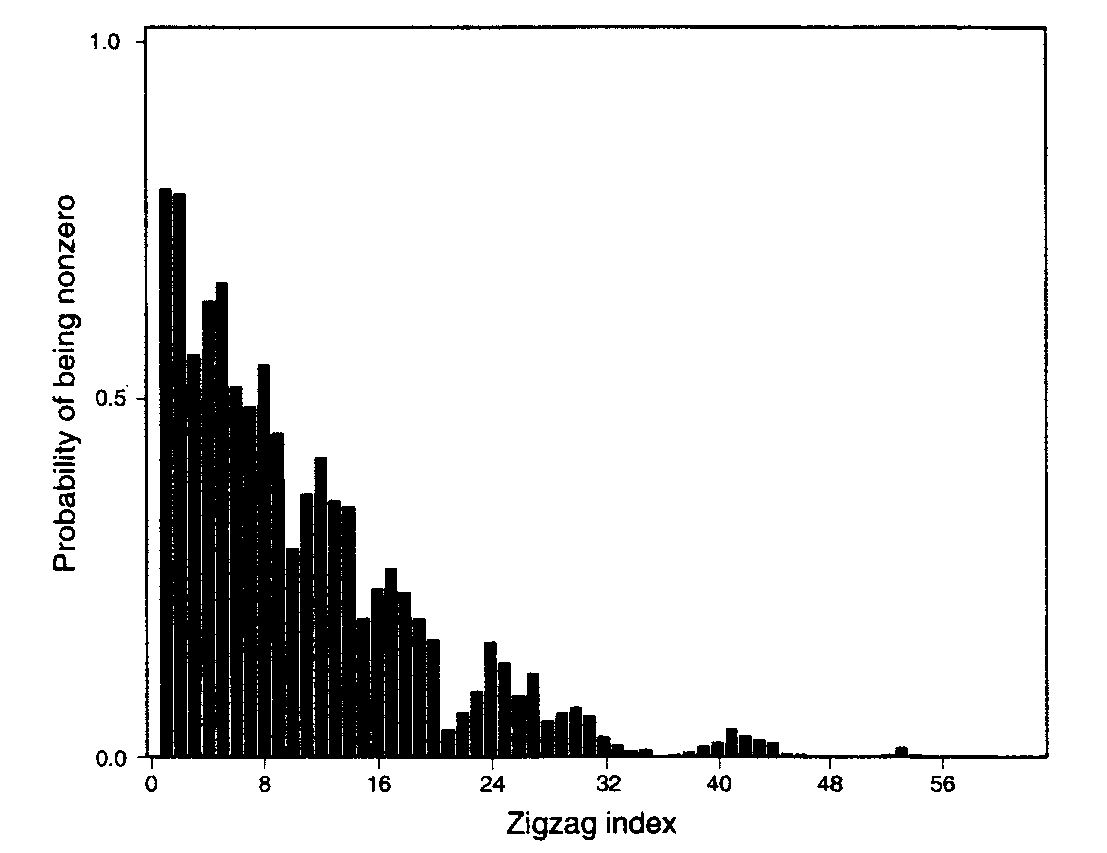
Probability of Quantised data being zero [1]
When decoding the JPEG image, the decoder first rebuilds the two dimensional matrix by reversing the zig zag ordering algorithm. The de-quantisation process then simply multiplies the input coefficients by the relevant quantisation factor to get an approximation for the original DCT coefficient matrix. Obviously a small quantisation factor will give a better estimate for the original coefficient, as the error range is half the quantisation factor.
Entropy Coding is a form of compression that relies on developing "code" words in a library for the input values or "symbols".
A very simple implementation of entropy coding would be to describe four kinds of weather by a 2 bit binary code as follows
|
Symbol |
Bit Code |
|
Clear |
00 |
|
Cloudy |
01 |
|
Rainy |
10 |
|
Snowy |
11 |
This would allow a coding algorithm to describe the weather with two bits of information per sample. This is a "fixed length" code. Fixed length codes are best applicable to applications where each of the symbols are equally likely, that is to say where each of the weather types is 25% likely in the above example.
In most real world applications this is not the case, each of the symbols actually have different probabilities of occurring. This leads to the use of "variable length" codes. If an event is most likely to happen more often than the other events, then it makes sense to use a code word that is actually shorter, or requires less information, than the other event codes.
Using the weather example again, say that each event has a probability as follows, we can generate variable length codes
|
Symbol |
% Prob |
Bit Code |
|
Clear |
50 |
0 |
|
Cloudy |
25 |
10 |
|
Rainy |
12.5 |
110 |
|
Snowy |
12.5 |
111 |
Now we can determine the average bit length for a code per symbol.
![]()
As can be seen, an average of 1.75 bit/symbol is more efficient then the 2 bits/symbol that the fixed length code produced.
The codes produced for this example are found using Huffman coding, which is one of the two options that the JPEG standard allows for. The other is known as Arithmetic Coding. This project uses Huffman Coding for the following reasons
Huffman Coding is simpler.
Arithmetic Coding is patented and hence has restrictions on its use.
Unfortunately Arithmetic Coding is superior to Huffman Coding in terms of speed and efficiency. However using a patented technology is beyond the scope of this project. Arithmetic Coding partly gains its superiority by being "adaptive", ie being able to produce probability estimates on the fly. Huffman coding on the other hand requires a set of constant probabilities for each of the symbols prior to encryption.
Huffman codes are generally derived use a coding "tree" structure. This tree is built by a sequence of pairing operations in which the two least probable symbols are joined at a node. This continues with each node having their probabilities combined and then paired with the next smallest probable symbol until all the symbols represented in the tree structure.
Creating a code from this tree structure is done by assigning a 0 or a 1 bit to each branch of the tree. The code for each symbol is then read by concatenating each bit from the branches, starting at the centre of the structure and extending to the branch for which the relevant symbol is defined.
Following this procedure gives a unique code for each symbol of optimal data size.
Note that even though the codes can have different lengths, one code can never be mistaken for another if read from the most significant bit to the least significant bit. This becomes important in JPEG encoding as bit codes are appended to each other without regard for the length of the code.
Fortunately, the JPEG standard provides a number of tables of Huffman codes to describe the different ways that the input quantised data is to be encrypted.
The quantised DCT coefficients tend to have two different styles of values within them.
The first is the DC coefficient or the first value in the zig-zag ordered array. This value is always the average value and as such is likely to be any number within the range permitted.
The second is all of the AC values (the second through to last coefficient in the zig-zag ordered array). The values of the coefficients are likely to be close to zero, with the likelihood of being zero increasing as the coefficients near the end of the array.
These two types of information are different enough to warrant separating them and applying different methods of coding to get the optimal compression efficiency.
Additionally, coding in JPEG also distinguishes between whether the data is Luminance or Chrominance information. To do this it allows for different code tables to be specified for each of the components, much the same as how the quantisation tables are defined.
This means that a total of four Huffman code tables are generally defined in colour images, two for DC information and 2 for AC information. Again, if the image was grey scale only two tables would be required (1 DC and 1 AC).
While the DC coefficient of the input array is fairly unpredictable by itself, the property of real world images to not have a great deal of change in a localised area can be used to predict the current DC coefficient value. By using a differential prediction model (DPCM) we can increase the probability that the value we encode will be small.
To obtain this value we simply subtract the DC coefficient from the previously processed 8x8 block in the same component from the DC coefficient of the current block. This value is called the "DPCM difference" or the "DIFF"
Once this DIFF value is calculated, it is compared to the following table to identify the symbol group that it belongs to (SSSS in the following diagram). The Huffman code that this symbol is described by is defined in the code tables that the JPEG standard provides (these tables are provided as an attachment to this report).
|
SSSS |
DPCM Difference |
Precision | |||||||
|
DCT-Based |
Lossless | ||||||||
|
0 |
0 |
8 |
12 |
2 |
-16 | ||||
|
1 |
-1 |
, |
1 |
8 |
12 |
2 |
-16 | ||
|
2 |
-3,-2 |
, |
2,3 |
8 |
12 |
2 |
-16 | ||
|
3 |
-7,..,-4 |
, |
4,..,7 |
8 |
12 |
3 |
-16 | ||
|
4 |
-15,..,-8 |
, |
8,..,15 |
8 |
12 |
4 |
-16 | ||
|
5 |
-31,..,-16 |
, |
16,..,31 |
8 |
12 |
5 |
-16 | ||
|
6 |
-63,..,-32 |
, |
32,..,63 |
8 |
12 |
6 |
-16 | ||
|
7 |
-127,..,-64 |
, |
64,..,127 |
8 |
12 |
7 |
-16 | ||
|
8 |
-255,..,-128 |
, |
128,..,255 |
8 |
12 |
8 |
-16 | ||
|
9 |
-511,..,-256 |
, |
256,..,511 |
8 |
12 |
9 |
-16 | ||
|
10 |
-1023,..,-512 |
, |
512,..,1023 |
8 |
12 |
10 |
-16 | ||
|
11 |
-2047,..,-1024 |
, |
1024,..,2047 |
8 |
12 |
11 |
-16 | ||
|
12 |
-4095,..,-2048 |
, |
2048,..,4095 |
12 |
12 |
-16 | |||
|
13 |
-8191,..,-4096 |
, |
4096,..,8191 |
12 |
13 |
-16 | |||
|
14 |
-16383,..,-8192 |
, |
8192,..,16383 |
12 |
14 |
-16 | |||
|
15 |
-32767,..,-16384 |
, |
16384,..,32767 |
12 |
15 |
-16 | |||
|
16 |
32768 |
-16 | |||||||
Huffman Coding of DPCM Differences [1]
However this does not completely describe the DIFF coefficient as the SSSS code is only for a range of absolute values, except of course if the DIFF is zero. The full code is created when a number of additional bits are appended to the SSSS code stream to identify the sign and fully specify the magnitude of the DIFF. These additional bits are defined in the following diagram.
|
SSSS |
DPCM Difference |
Additional Bits | ||||||
|
(binary) | ||||||||
|
0 |
0 |
- |
||||||
|
1 |
-1 |
, |
1 |
0 |
, |
1 | ||
|
2 |
-3,-2 |
, |
2,3 |
00,01 |
, |
10,11 | ||
|
3 |
-7,..,-4 |
, |
4,..,7 |
000,..,011 |
, |
100,..,111 | ||
|
4 |
-15,..,-8 |
, |
8,..,15 |
0000,..,0111 |
, |
1000,..,1111 | ||
|
: |
: |
: |
||||||
|
: |
: |
: |
||||||
|
16 |
32768 |
- |
||||||
Additional bits for Huffman DPCM coding [1]
As can be seen the code to be appended is found by taking the SSSS low order bits of the DIFF if the DIFF is positive. If the DIFF is negative then one is subtracted from the DIFF (the twos complement representation of the negative DIFF) and taking the SSSS low order bits is the code to be appended.
Note that the JPEG baseline standard only allows for 12 bit DPCM values (the DCT output was 12 bit, following from an 8 bit input sample), so a value of SSSS of 11 is the maximum supported.
In the special case of the first 8x8 pixel section of the component being processed, the DIFF is assigned the value of the current DC coefficient value (ie the previous section DC coefficient is zero).
Note that the Huffman code tables for SSSS can be different depending on which component is currently being processed. If the JPEG standard libraries are being used then there is one each for luminance and chrominance components. The additional bits that get appended to the SSSS codes are always the same, irrespective of the component being processed.
The AC coefficients are coded using a substantially different procedure then the DC coefficient version.
Because the value of the AC coefficients tends to be close to zero after the quantisation step of the JPEG algorithm, the coding of these coefficients manipulates long runs of zeroes.
The selection of a symbol is based on a combination of the number of zeroes (RRRR) that preceded the current coefficient and the range of the current coefficient. The range is calculated by the same method as it was in the DC coefficient case, selecting the SSSS symbol from the following figure.
|
SSSS |
AC Coefficients |
Precision | |||||||
|
DCT-Based |
Lossless | ||||||||
|
0 |
0 |
8 |
12 |
2 |
-16 | ||||
|
1 |
-1 |
, |
1 |
8 |
12 |
2 |
-16 | ||
|
2 |
-3,-2 |
, |
2,3 |
8 |
12 |
2 |
-16 | ||
|
3 |
-7,..,-4 |
, |
4,..,7 |
8 |
12 |
3 |
-16 | ||
|
4 |
-15,..,-8 |
, |
8,..,15 |
8 |
12 |
4 |
-16 | ||
|
5 |
-31,..,-16 |
, |
16,..,31 |
8 |
12 |
5 |
-16 | ||
|
6 |
-63,..,-32 |
, |
32,..,63 |
8 |
12 |
6 |
-16 | ||
|
7 |
-127,..,-64 |
, |
64,..,127 |
8 |
12 |
7 |
-16 | ||
|
8 |
-255,..,-128 |
, |
128,..,255 |
8 |
12 |
8 |
-16 | ||
|
9 |
-511,..,-256 |
, |
256,..,511 |
8 |
12 |
9 |
-16 | ||
|
10 |
-1023,..,-512 |
, |
512,..,1023 |
8 |
12 |
10 |
-16 | ||
|
11 |
-2047,..,-1024 |
, |
1024,..,2047 |
8 |
12 |
11 |
-16 | ||
|
12 |
-4095,..,-2048 |
, |
2048,..,4095 |
12 |
12 |
-16 | |||
|
13 |
-8191,..,-4096 |
, |
4096,..,8191 |
12 |
13 |
-16 | |||
|
14 |
-16383,..,-8192 |
, |
8192,..,16383 |
12 |
14 |
-16 | |||
|
15 |
-32767,..,-16384 |
, |
16384,..,32767 |
12 |
15 |
-16 | |||
|
16 |
32768 |
-16 | |||||||
Huffman Coding of AC Coefficients [1]
The "RUN-SIZE" symbol is then selected by cross referencing the RRRR and SSSS values in the following figure, once found the code for this symbol can be found by searching through the tables that the JPEG standard provides (and are attached to this report as an appendix)
|
SSSS | ||||||||||||
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 | ||
|
0 |
EOB |
01 |
02 |
03 |
04 |
05 |
06 |
07 |
08 |
09 |
0A | |
|
1 |
N/A |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
1A | |
|
2 |
N/A |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
2A | |
|
3 |
N/A |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
3A | |
|
4 |
N/A |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
48 |
49 |
4A | |
|
R |
5 |
N/A |
51 |
52 |
53 |
54 |
55 |
56 |
57 |
58 |
59 |
5A |
|
R |
6 |
N/A |
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 |
69 |
6A |
|
R |
7 |
N/A |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
7A |
|
R |
8 |
N/A |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
88 |
89 |
8A |
|
9 |
N/A |
91 |
92 |
93 |
94 |
95 |
96 |
97 |
98 |
99 |
9A | |
|
10 |
N/A |
A1 |
A2 |
A3 |
A4 |
A5 |
A6 |
A7 |
A8 |
A9 |
AA | |
|
11 |
N/A |
B1 |
B2 |
B3 |
B4 |
B5 |
B6 |
B7 |
B8 |
B9 |
BA | |
|
12 |
N/A |
C1 |
C2 |
C3 |
C4 |
C5 |
C6 |
C7 |
C8 |
C9 |
CA | |
|
13 |
N/A |
D1 |
D2 |
D3 |
D4 |
D5 |
D6 |
D7 |
D8 |
D9 |
DA | |
|
14 |
N/A |
E1 |
E2 |
E3 |
E4 |
E5 |
E6 |
E7 |
E8 |
E9 |
EA | |
|
15 |
ZRL |
F1 |
F2 |
F3 |
F4 |
F5 |
F6 |
F7 |
F8 |
F9 |
FA | |
Huffman AC Statistical Model Run-Length/Amplitude Combinations [1]
As can be seen from this figure there are two special codes defined, ZRL and EOB. EOB is the special case of their being no non-zero coefficient values in the current array. ZRL is the special case of there being 16 zeroes in sequence and there are more non-zero coefficient values in the remainder of the array.
Again, as per the DC case, additional bits are required to complete the code for the RUN-SIZE symbol with the magnitude and sign information of the non-zero component of the symbol. Referring to the following figure gives the bits required.
|
SSSS |
AC Coefficients |
Additional Bits | ||||||
|
(binary) | ||||||||
|
0 |
0 |
- |
||||||
|
1 |
-1 |
, |
1 |
0 |
, |
1 | ||
|
2 |
-3,-2 |
, |
2,3 |
00,01 |
, |
10,11 | ||
|
3 |
-7,..,-4 |
, |
4,..,7 |
000,..,011 |
, |
100,..,111 | ||
|
4 |
-15,..,-8 |
, |
8,..,15 |
0000,..,0111 |
, |
1000,..,1111 | ||
|
: |
: |
: |
||||||
|
: |
: |
: |
||||||
|
16 |
32768 |
- |
||||||
Additional bits for Huffman AC Coefficients coding [1]
Note that this is identical to the figure given for the additional bits in the DC coefficient section.
The AC coefficients are processed from the first (or lowest order) AC coefficient in the zig-zag array through to the last coefficient (or 64th) value in the array. Obviously in practise, the array is scanned through until a non-zero value is found, or 16 zeroes in sequence are found.
A typical run of codes being output from this procedure is one to three RUN-SIZE symbol codes and one EOB symbol code.
Note that the Huffman code tables for RUN-SIZE can be different depending on which component is currently being processed. If the JPEG standard libraries are being used then there is one each for luminance and chrominance components. The additional bits that get appended to the RUN-SIZE codes are always the same, irrespective of the component being processed.
When decoding the JPEG encoded data stream, the decoder simply searches through the relevant Huffman code library (ie DC or AC, Luminance or Chrominance) that is stored within the JPEG file for a code that matches the current bit stream. Because each code is guaranteed to be unique (even codes of different lengths) there is no problem in finding the correct symbol that the code is representing.
The File format that was used for this project was JFIF (JPEG File Interchange Format). This is not strictly a part of the JPEG standard, but was developed to attempt to standardise the JPEG formats so that greater compatibility between platforms and applications could be obtained. Currently JFIF is the main file format that is used, especially for JPEG Baseline compressed images.
The JPEG standard defines a number of header fields and sections to allow the JPEG encoded image to be decoded. It also left a number of sections open so that applications could make use of them as they saw fit. The result was that a large amount of incompatible versions of JPEG were released, as the header format of the file were not compatible. JFIF solved this problem by standardising the application specific sections so that compatibility could be introduced.
There are quite a number of header sections in the JPEG that defined, but are not applicable in JPEG baseline. For simplicity this section will only document the sections that this project actually used, but the reader should be aware that there a quite a few more.
|
Description |
Symbol |
Marker |
|
Baseline DCT, Huffman |
SOF0 |
FFC0H |
|
Extended sequential DCT, Huffman |
SOF1 |
FFC1H |
|
Progressive DCT, Huffman |
SOF2 |
FFC2H |
|
Spatial (sequential) lossless, Huffman |
SOF3 |
FFC3H |
|
Differential Sequential DCT, Huffman |
SOF5 |
FFC5H |
|
Differential progressive DCT, Huffman |
SOF6 |
FFC6H |
|
Differential spatial, Huffman |
SOF7 |
FFC7H |
|
Reserved for JPEG extensions, Arithmetic |
JPG |
FFC8H |
|
Extended sequential DCT, Arithmetic |
SOF9 |
FFC9H |
|
Progressive DCT, Arithmetic |
SOF10 |
FFCAH |
|
Spatial (sequential) lossless, Arithmetic |
SOF11 |
FFCBH |
|
Differential sequential DCT, Arithmetic |
SOF13 |
FFCDH |
|
Differential progressive DCT, Arithmetic |
SOF14 |
FFCEH |
|
Differential spatial, Arithmetic |
SOF15 |
FFCFH |
|
Define Huffman Table(s) |
DHT |
FFC4H |
|
Define Arithmetic coding conditioning |
DAC |
FFCCH |
|
Restart |
RSTm |
FFD0-FFD7H |
|
Start of Image |
SOI |
FFD8H |
|
End of Image |
EOI |
FFD9H |
|
Start of Scan |
SOS |
FFDAH |
|
Define Quantisation Table |
DQT |
FFDBH |
|
Define number of Lines |
DNL |
FFDCH |
|
Define Restart Interval |
DRI |
FFDDH |
|
Define Hierarchical progression |
DHP |
FFDEH |
|
Expand reference components |
EXP |
FFDFH |
|
Reserved for Application Segments |
APPn |
FFE0-FFEFH |
|
Reserved for JPEG extensions |
JPGn |
FFF0-FFFDH |
|
Comment |
COM |
FFFEH |
|
Temporary arithmetic Coding |
TEM |
FF01H |
|
Reserved |
RES |
FF02-FFBFH |
Complete List of Available Segments in JPEG
This segment is always 2 bytes long and always contains the marker FFD8H
JFIF Application (APP0) Segment
This segment contains the following information in order. The purpose of this segment is to define higher level details such as image size and miscellaneous version control information. The number in brackets indicates the number of bytes the information is stored in.
Define Quantisation Table (DQT) Segment
This segment contains information detailing the Quantisation Tables for the encoded image. The number in brackets indicates the number of bytes the information is stored in.
Steps 3 and 4 are repeated for each Quantisation table defined.
This segment details information at a lower level such as which component uses what Quantisation table, sampling factors etc. The number in brackets indicates the number of bytes the information is stored in.
Steps 7 through 9 are repeated for each component used in the image. JFIF also specifies that if the YCbCr colour format is used, then the component ID for Y should be 01H, the ID for Cb should be 02H and Cr should be 03H.
Define Huffman Table (DHT) Segment
This segment defines the contents of the Huffman Code Libraries. This entire segment is repeated once for each Huffman Code Library used. The number in brackets indicates the number of bytes the information is stored in.
Note that if the JPEG Standard Huffman code libraries are being used, then the entries for steps 4 and 5 are defined in the standard (also they are attached to this report as an appendix).
This segment contains header information as well as actual scan data. Multiple SOS Segments can be found if there is more than one scan. The number in brackets indicates the number of bytes the information is stored in.
Steps 4 and 5 are repeated for each component defined in the SOF segment
Appended to this is the actual compressed image data.
Each consecutive MCU data is added bit by bit with no padding. Ie there are no byte boundaries from one MCUs data to the next. The only padding that occurs is at the end of the scan when the remaining bits in the last byte to be filled with 1’s if the byte is incomplete.
If ever, throughout the scan, a situation occurs where a byte contains an FFH then a 00H must be inserted after it to ensure the decoder does not mistake it for a new segment.
This segment is always 2 bytes long and always contains the marker FFD9H.